

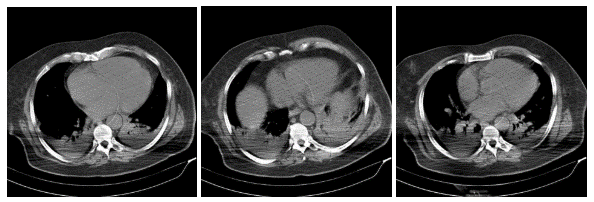
![A rough 3D model obtained from a mobile video scan [Source: Linköping University]](https://fabbaloo.com/wp-content/uploads/2020/05/image-asset_img_5eb0a77a177c8.jpg)
Have you heard of “continuous-time structure from motion”? You may hear a lot more soon.
The concept of continuous-time structure from motion is an approach for developing a 3D understanding of a scene from 2D video capture, even live video.
The function is surely necessary as a vision component for future mobile robotic systems that must navigate through the real world: they have visual systems but need to know where the walls, cliffs and obstacles are located.
It’s now possible to do this, at least theoretically, because many modern imaging systems include not only high-power optical sensors, but also include internal motion sensors that track the orientation and movement of the camera. If you have a view and an exact position, you can do interesting things.
This is done by treating the successive video frames as still images representing a kind of “trajectory” through the real 3D scene. By using advanced mathematical approaches, it’s possible to develop a 3D model of a scene. We’ve previously written about this technique, known as photogrammetry.
But video is quite different. In photogrammetry you must set up a series of still images taken from all directions, with equal lighting on all sides. This is a relatively slow process and requires a stationary subject. It’s entirely inadequate for real-time decisions made by, say, a mobile robot.
But doing the same type of process on video may be the answer for robotics. If it were possible to perform the required algorithms in real time on a video stream, a 3D model of the surrounding area could be obtained. Then other robotic logic could leverage that to make better decisions about movement (or targeting, I suppose).
![3D trajectory concept using a rolling shutter imaging platform [Source: Linköping University]](https://fabbaloo.com/wp-content/uploads/2020/05/image-asset_img_5eb0a77a6dbe2.jpg)
A new research paper from Linköping University by Hannes Ovrén and Per-Erik Forssén seems to develop an improved version of this concept. They explain:
“Platforms that house both cameras and inertial sensors are now very common. Examples include most current smartphones and tablets, but also some action cameras, e.g. newer models from GoPro. Nearly all such platforms use cameras with an electronic rolling shutter mechanism, that acquires each frame in a row-by-row fashion. This lends itself naturally to continuous-time motion models, as the camera has a slightly different pose in each image row.”
And:
“We replace the SE(3)-based interpolation used in the Spline Fusion method (Lovegrove et al. 2013; Patron-Perez et al. 2015) with a split interpolation in R3 and SO(3). This leads to a trajectory representation that does not couple rotation and translation in a screw motion, see Figure 6, and is better suited to e.g., hand-held camera motions.”
While their paper is quite detailed and requires a very good understanding of advanced math, what’s important to me is that last bit: “hand-held camera motions”. It seems that their approach could enable the development of effective handheld 3D scanners that could rapidly capture a 3D model of a subject merely by running around them with an appropriate smartphone app.
![Imaging devices used to perform video to 3D model capture [Source: Linköping University]](https://fabbaloo.com/wp-content/uploads/2020/05/image-asset_img_5eb0a77ac06e3.jpg)
While there are smartphone apps that perform 3D scanning today, they are rather formal in their execution and have significant constraints. Algorithms based on the new research might be able to break that barrier and open up the possibility of widespread 3D scanning by the general public.
I have no idea where the research will head commercially, but that’s my hope. However, it’s likely it will first show up for use in robotic systems as described above.
But I’ll wait.
Via Arxiv (PDF)







Anna Shcherbinina has been working at Artec 3D for nine years.