

NVIDIA Researchers have developed an improved technique for automatically generating 3D models from text input.
Many Fabbaloo readers will be somewhat familiar with the increasingly popular (and controversial) Text-to-Image systems. These accept a text “prompt” and quickly generate a series of highly detailed and artistic images of the request. The technology is set to revolutionize the world of images, and is still under development by a number of parties.
The concept has been extended to other realms, including the generation of music, text and others. One of them is, incredibly, “Text-to-3D Model”. That’s right, you can literally ask for a 3D model and one can be generated.
There are few examples of this presently. One we are aware of is from Luma Labs. The company has been developing a NeRF-based 3D scanning system, which we tested recently. (“NeRF” = “Neural Radiosity Field”.) Then the company suddenly announced a new experimental feature to generate 3D models from text input by leveraging their existing system. The implications of this technology are staggering.
Another example is DreamFusion, an open source project that provides Text-to-3D services.
However, there are problems. The NeRF processing can take a very long time to complete, which implies the need for lots of expensive hardware. In addition, the 3D models generated tend to have fewer details due to the resolution of the imagery being generated in the process.
Now it turns out that NVIDIA has been working on this problem and has developed an approach for solving these issues.
Their experimental Magic3D system provides “high resolution text to 3D content creation”.
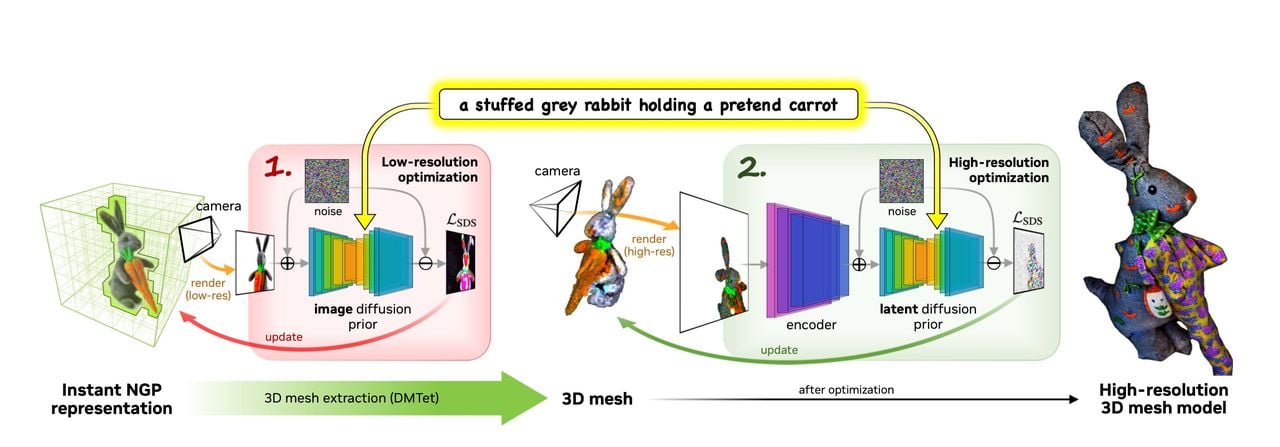
How is this accomplished? Magic3D has a two stage approach, where the first stage produces a coarse 3D model. This allows for speedier processing. Then a second stage takes the coarse model and refines it to a higher resolution.

The paper explains the speed achieved by this approach:
“We benefit from both efficient scene models and high-resolution diffusion priors in a coarse-to- fine approach. In particular, the 3D mesh models scale nicely with image resolution and enjoy the benefits of higher resolution supervision brought by the latent diffusion model without sacrificing its speed. It takes 40 minutes from a text prompt to a high-quality 3D mesh model ready to be used in graphic engines.”
Because of the two-stage approach, it is also possible to refine poor 3D models by injecting them into the process. This is similar to the “img2img” approach used by the AI image systems.
This development is significant, but still one step along the way towards a world where we can quickly ask for 3D models and completely avoid the use of CAD tools. My expectation is that this will first become usable for organic models, like sculptures and figurines. Later the process could evolve into a new way to design 3D models of mechanical parts, and the iterative approach enabled by this research could perhaps help a designer through a complex design process.
Via NVIDIA Research and Arxiv