

A new CMU framework uses large language models to spot defects and change print parameters during print jobs. 
Material Extrusion (MEX) remains the most common additive manufacturing process, but it is also famously fragile. Filament variability, nonstandard hardware mods, slicer quirks, and plain human error stack up into surprisingly high failure rates: the paper’s authors say there is a 20% failure for PLA prints, a 34% material waste rate for ABS prints, and overall failure rates that can reach 41.1%, with human error responsible for 26.3% of failures. Anyone operating a desktop 3D printer will agree with these figures. 
Most automated monitoring approaches in this space fall into two buckets. Rule based systems can be fast, but they tend to be brittle when you change printers, lighting, or materials. Deep learning can work well, but it usually needs big labeled datasets and often ends up tuned to a narrow set of defect classes or a single printer setup. The practical reality is that many labs and print farms do not want to run dozens of sacrificial builds just to train a detector for one machine.
This new paper from Carnegie Mellon University proposes a different approach: use a multimodal large language model as a reasoning layer that can look at images, decide what is going wrong, query the printer state, and then push corrections back through the printer’s API.
The research team calls this a “rule free” approach because they do not fine tune the model on a 3D printing defect dataset; instead, the system relies on in context learning and structured prompts. 
A Seven Agent Workflow Wrapped Around Klipper
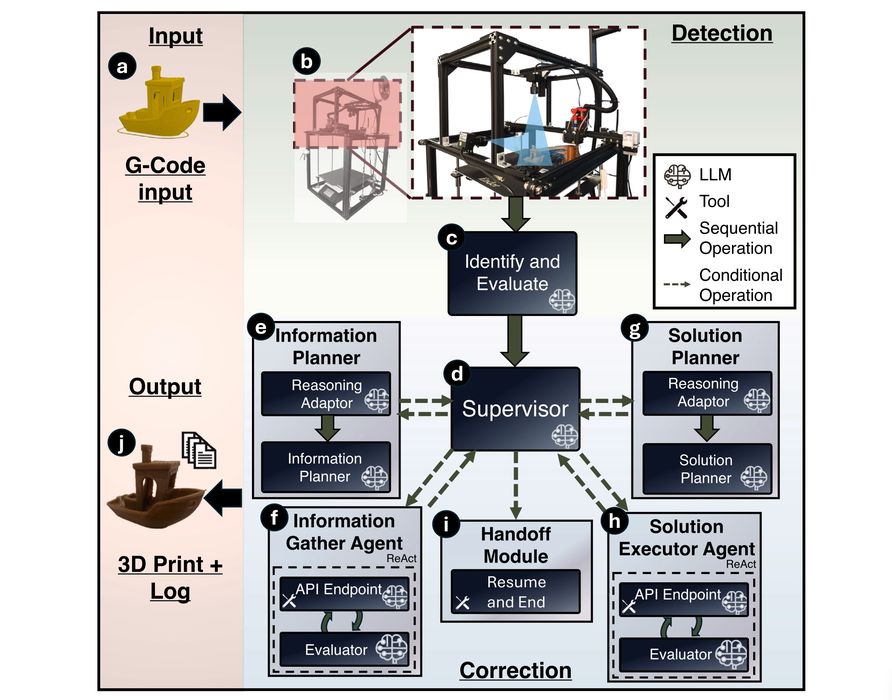
Their implementation used Klipper firmware with Crowsnest for camera streaming, Moonraker for API access, and Mainsail as the interface, then connected a Python based multi agent system built on LangChain and LangGraph. 
The hardware testbed was a Creality Ender 5 Plus and a Creality Ender 3, each outfitted with two frame mounted cameras (top and front views).
After each layer, the printer pauses, parks the toolhead, captures images, and hands them to the model along with a natural language description of the part. A supervisor agent then orchestrates specialist agents: one for image based reasoning, planners for information gathering and solution generation, and executors that call printer API endpoints to retrieve parameters and apply changes. 
One interesting approach stands out: they restricted the command surface area after early tests showed that dumping full firmware documentation into the model could exceed context limits and even trigger unintended shutdown behavior. The final setup uses a curated list of modifiable commands, explicitly excluding sensitive actions like shutdown, restart, or permanent firmware modification. That’s an important lesson for anyone tempted to “just give the model everything.” 
What The LLM Actually Changes, And What Improved
In experiments, the system detected common MEX failures including inconsistent extrusion, stringing, warping, and layer adhesion problems, then adjusted parameters such as flow rate, print speed, Z offset, fan speed, retraction settings, and nozzle temperature. 
The team deliberately ran a nonstandard 1 mm nozzle on machines that typically assume smaller diameters, creating a situation where default slicer profiles are less reliable. In single layer tests (a 100 x 100 mm square at 0.5mm height), the model pushed changes like reducing speed to improve adhesion, nudging flow rate above 100% to address under extrusion, and tuning retraction to reduce oozing. For TPU, it raised nozzle temperature to 220C to improve flow and layer bonding.
They also report a latency cost: each layer analysis took about 15 to 45 seconds depending on defect complexity and how quickly the agent found the right API endpoint. That is quite expensive in terms of job time, and it is one reason the paper suggests sampling every few layers as a future optimization path. It’s also possible that after a while the material is “dialed in” and no further measurements might be required. 
Where this gets more interesting is the mechanical validation. Compression tests on several geometries showed higher peak load capacity for LLM optimized prints, including a reported 5X increase for a square structure, 1.6X for a hexagonal unit cell, 1.3X for a hemisphere, and 2.5X for an auxetic structure. 
Why This Matters, And Where It Might Break
If the results hold up across more printers and more chaotic real world conditions, the biggest value may be labor reduction rather than perfect defect taxonomy. A system that can catch under extrusion early, compensate for a bad parameter choice baked into supplied GCODE, and document every intervention could be attractive for print farms, teaching labs, and service bureaus running mixed jobs. 
However, the limitations of the approach are significant. Some defects are out of scope or inherently hard to correct: elephant foot happens in early layers, cracks often emerge after cooling, and ringing tends to be hardware induced. The authors also note occasional misclassification of visually similar issues like blobs versus stringing, influenced by image downscaling and token constraints.
The big question is whether LLM control becomes a standard “software upgrade” for MEX, or whether it stays a clever lab demo until printers expose safer, more structured control interfaces by design. Perhaps someday our 3D printers will be smart enough to tune themselves.
Via Science Direct